TMR and TCFP
Common Excel sheet for calculation
Halada’s presentation at EcoBalance2024 (2024/11/6)


The Circular Economy is a departure from the linear economy of material dependence on oil and iron, which was cheap and readily available.
To do so, we must recognize how expensive natural blessings such as resources that we have considered “inexpensive and readily available” have been.
Resource efficiency and circularity must not be discussed only within the human economic sphere, but must be discussed in relation to the degree of dependence on the general circulation with the Global Environment Institute.
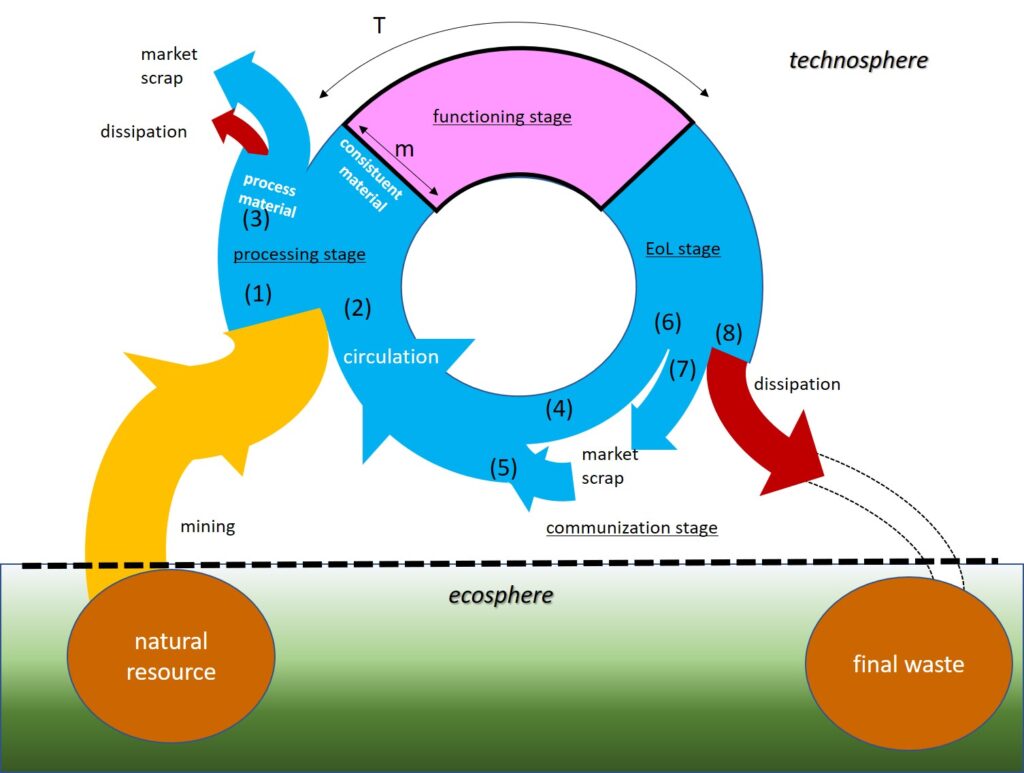
The famous butterfly diagram has also been extended with biomass, but unfortunately not enough with regard to this circularity dependence with the Global Environment Institute. Also. Quantitatively grasping the degree of circulation dependence with the Institute for Global Environmental Research (IGES) is of great significance to Nature Positive’s efforts to recognize where we are now.
So, was there an indicator to quantify its cyclical dependence with the Institute for Global Environmental Studies? The answer is yes. Schmidt-Blake of the Butterpal Institute in Germany presented the concept of ecological rucksacks in the 1990s, which was developed into the material intensity by Waitzsekker and others, which led to the creation of concepts such as 2-factor 4 for halving or quartering the material intensity, and which has become This is one of the origins of the current circular economy.
This concept was inherited by his successors at the Butterfly Parr Institute and by Harada at NIMS, and its quantitative value was calculated as Total Material Requirement, which was used as a supplementary indicator in Japan’s Basic Environmental Plan.
However, the discussion of material use and circulation shifted to availability and effective use within the human economic sphere, and TMR was regarded as one of the environmental factors and retreated to the successor of the discussion as it was not a factor that could be directly linked to the toxicological perspective from that environmental factor perspective.
Even as the concept of encompassing material intensity as a Circular Economy became more important, this concept of TMR was not given attention except by a few researchers.
However, as the Nature Positive has become a rallying cry along with the Circular Economy, the Circular Economy needs to focus on “cheap and accessible material and energy new greats.” TMR needs to be reevaluated as a quantitative method to understand how dependent the human economy has been on nature, and resource efficiency must be discussed as a means of reducing this dependence.
What is TMR, then, the total amount of resources input to produce a certain substance or product? To quantify resources here, we use the amount of earth, rocks, and water. Biomass is of course a resource, but it is difficult to quantify because it does not exist at the boundary between the human economy and the global environment. How much soil and water are moved is quantified as a first approximation between the global environmental sphere and human economic activity. In the past, the “sand on the beach theory” held that TMR could not be added to environmental stressors as a number that may have no environmental impact if a handful of sand on the beach is moved from right to left. However, now that Nature Positive has been done and barrels are being used. We all know by now that there are diverse ecosystems in the sand of the beach.
Specifically, the amount of earth, rocks, and water involved is accumulated from the boundary between human activities and the global environment sphere, such as ore mining and wastewater treatment. For example, iron production requires the input of iron ore, coke, limestone, and water, and slag treatment. The iron ore is mined in iron mines and then processed. Water and flotation agents are used for ore dressing, and sludge treatment occurs. The mining of ore involves the use of large quantities of earth and rocks, as well as frequent transportation with diesel oil, explosives (ANFO), lubricating oil, and even water. ammonium sulfate and diesel oil are used to produce ANFO. The flotation agent is also synthesized from ethanol, carbon disulfide, and sodium hydroxide. Ammonium sulfate is made from ammonia and sulfuric acid. Ammonia is synthesized from nitrogen and hydrogen, and sulfuric acid is synthesized from sulfur and water, resulting in waste acid treatment. Sulfur is mined from mines, while nitrogen and oxygen are fractionated from air at low temperatures. Light oil is also fractionated from crude oil, but crude oil mining also involves drilling fluids, bentonite, flocculants, and sludge treatment. All of this was not mentioned, and all of this involves the input of electricity, which can be traced back to the natural resources of earth, water, and air. The total material requirement is the sum of those total quantities.
This method can also be applied to CFP (Carbon Footprint) by tracing CO2 emissions from the resource end part, and the carbon footprint obtained by this method is named Total Carbon Footprint. The reason why TCFP is used instead of CFP is described below.
Let us discuss another reason why TMR has not been widely used. It is the difficulty in obtaining data. There are two reasons for the difficulty in obtaining data. One is the complicated nested structure.
The second is the difficulty in obtaining information on the boundaries between the earth and the environment. Even if the grade of ore in a mine is disclosed to the public, the amount of exposed and excavated soil used to mine the ore is almost never made public because it is a management issue. For these reasons, the number of researchers who calculate or review the basic figures of TMR is extremely limited.
And that situation has changed dramatically. This is the birth of large-scale language-processing AI, often called generative AI. Although the term “generative AI” is often used to describe this type of AI, it is essentially a large-scale language processing AI based on “data”. In other words, the background of “generation” is “data mining” and collection. If we successfully prompt that AI and control the way data mining is done, we can make it collect mining data and waste processing data that could not be obtained before. I call this data mining ai.
Generative AI has the power to indirectly infer information that is not explicitly provided through natural language processing (NLP) for large-scale big data. In particular, they integrate diverse information from publicly available industry reports, technical papers, patent information, and online corporate reports to enable data estimation in the LCA process. These AIs automatically learn the knowledge necessary to build models and highly predict unknown information, thus contributing to improving the accuracy of TMR analysis.
The main advantages of using generative AI for data mining are as follows
The first is the ability to discover hidden patterns and trends in large volumes of unstructured data. This can complement process details not included in existing databases. Second, AI can analyze public information from around the world in real time, allowing it to respond quickly to new technologies and changing market trends. Third, even when it is difficult to acquire information through interviews or on-site surveys, AI can provide highly accurate estimates while keeping costs down.
Furthermore, generative AI goes beyond the limits of traditional data processing to provide integrated insights into complex systems and processes; in CFP evaluations of products involving advanced technologies such as DCR, AI-based estimation can be of great help in understanding the detailed environmental impact of each process. This makes it possible to obtain reliable results even in cases where accurate analysis is difficult due to insufficient data. In the future, the use of generative AI is expected to play an important role in improving the efficiency and accuracy of LCA assessments.
While there are many benefits to using generative AI for LCA data mining, there are also several concerns. These concerns should be considered in terms of the predictive accuracy of AI, ethical issues, reliability of information, and transparency and interpretability of data.
First, there is the issue of accuracy of estimation by generative AI: AI learns patterns based on past data and makes estimations, but the accuracy of predictions depends heavily on the quality of the data. process data required for LCA varies widely from industry to industry, and keeping up with the latest technologies and company operations can be It can be difficult to keep up with the latest technologies and company operations. Therefore, it is important to verify the accuracy of AI-based estimation results, which requires human expertise.
Second, the ethical issues associated with the use of AI cannot be ignored: AI collects and learns public information on the Internet, which may include information that has been disclosed in a manner not intended by the company or data that is highly confidential. The incorporation of such data into AI training poses the risk of indirect estimation and use of confidential corporate information. This could result in violations of privacy and information handling regulations.
Third, the reliability and interpretability of AI-provided results is also an important concern: AI-generated estimation results often function as a “black box,” and their decision criteria and estimation process tend to be opaque; because LCA is a scientific analysis, transparency and reproducibility of results are important, but if AI However, if it is not possible to explain how the estimates are derived, the reliability of the results may be undermined. Lack of transparency is also a serious problem when the results of LCA analysis influence corporate decisions and policies.
In addition, AI-based estimation involves the risk of bias because it relies on specific data; if the data set used by the AI for training is biased, the results may also be biased. This risks producing results that disadvantage certain countries or companies, or underestimating the true environmental impact.
Finally, the introduction of generative AI also entails a technical cost: a sophisticated computing environment and specialized knowledge are required to utilize AI, which is a heavy burden for the companies and organizations that implement it. In addition, in order to effectively utilize the results of AI analysis, know-how is required to accurately interpret the results and apply them in a way that meets the objectives of LCA.
As discussed above, the use of generative AI for data mining in LCA opens up many possibilities, but also entails multiple challenges, including accuracy of predictions, ethical issues, transparency, risk of bias, and implementation costs. To address these challenges, it is important to fully understand the use of AI and its limitations, and to strengthen its linkages with human expertise. In addition, transparent data management and guidelines for the proper handling of information must be developed.
First, 1) we assumed a range for the data values and allowed the AI to present not only a single estimate, but also its range (upper and lower bounds). This allows LCA calculations to account for uncertainty and include worst- and best-case scenarios in the analysis. For example, if energy consumption varies by region or operating conditions, the range can be taken into account for a more reliable assessment.
Next, 2) Validity determination was conducted using expert knowledge. Experts familiar with LCA and manufacturing processes scrutinized the estimated data of the generative AI to determine whether they were in line with reality, and eliminated inappropriate data or made adjustments to ensure the reliability of the results. For example, the results of AI’s estimation of the percentage of rare metals used were evaluated by materials engineering experts and checked in light of past performance data and the latest technical information.
Furthermore, 3) Prompting was devised to reduce bias in the AI’s learning process. Specifically, the AI was designed to input diverse information from multiple data sources to avoid bias toward a single viewpoint. For example, by combining environmental impact data from different regions and operational information from different companies, the AI avoids reliance on specific markets or technologies and provides comprehensive estimates.
The following measures were taken to devise prompts: First, the search scope of the generative AI was limited to highly specialized information in the form of “You are an expert in resource engineering and materials engineering and are familiar with LCA, industrial realities, and patents,” and the search priority for general blogs and non-specialized articles was lowered to Setting. This facilitated the acquisition of high-quality data.
Second, we specified in the target process designation “as a method of obtaining objects commonly used in industries around the world,” so that the AI would not rely on laboratory or idea-level information. This reduced the risk that commercially viable technologies and practical data would be prioritized and that information from the research stage, which has not yet been put to practical use, would be mixed in.
Furthermore, as a third measure, when the numerical value presented by the AI was far from the expert’s knowledge, we instructed the AI to consider the possibility that other information similar to the numerical value may have been mixed in, and to write the name and reaction equation of the relevant reaction. This had the effect of encouraging the AI to provide appropriate process-based information and preventing the inclusion of less relevant information.
Thus, data processing that maximizes the power of generative AI while incorporating expert judgment and a variety of data combinations is an effective method for ensuring high reliability in the CFP evaluation of complex materials. This is expected to improve the accuracy of LCA results by both managing uncertainty and reducing bias.
All the data thus obtained are documented on the website. As an expert in materials engineering, my checks have been made, but I hope that all of you will consider the validity of the data with your own eyes.
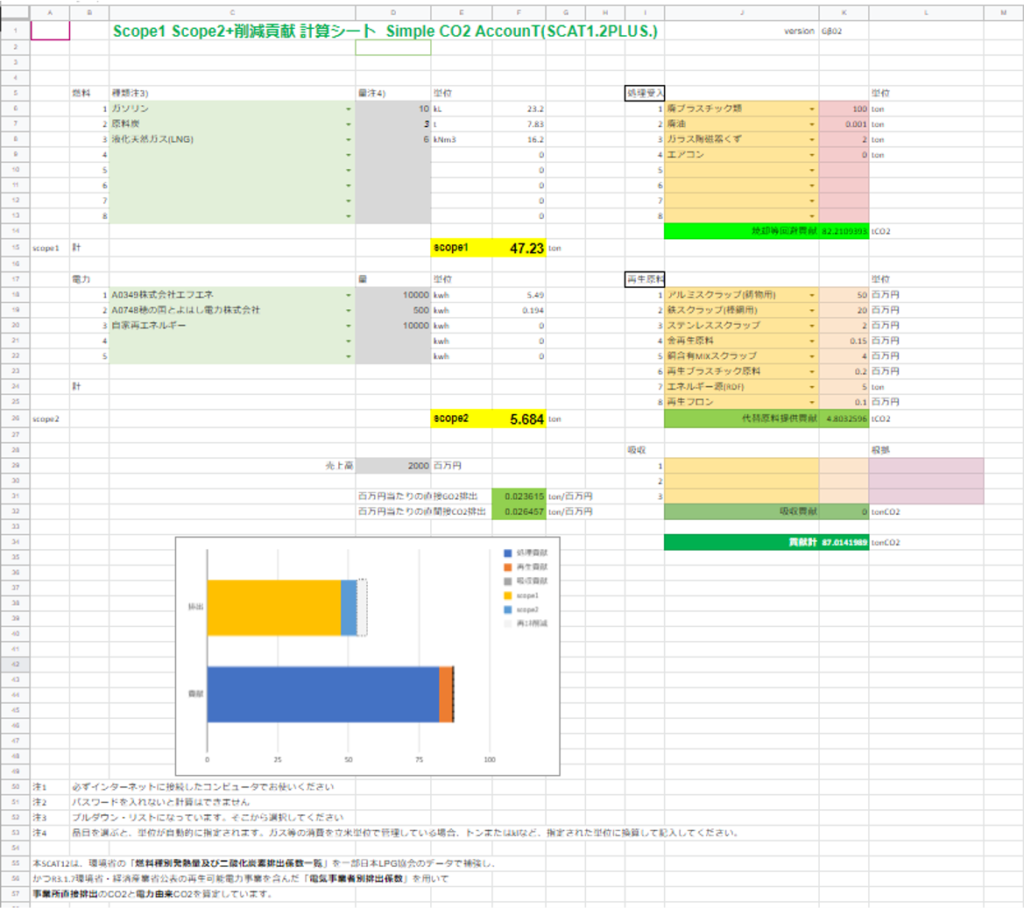
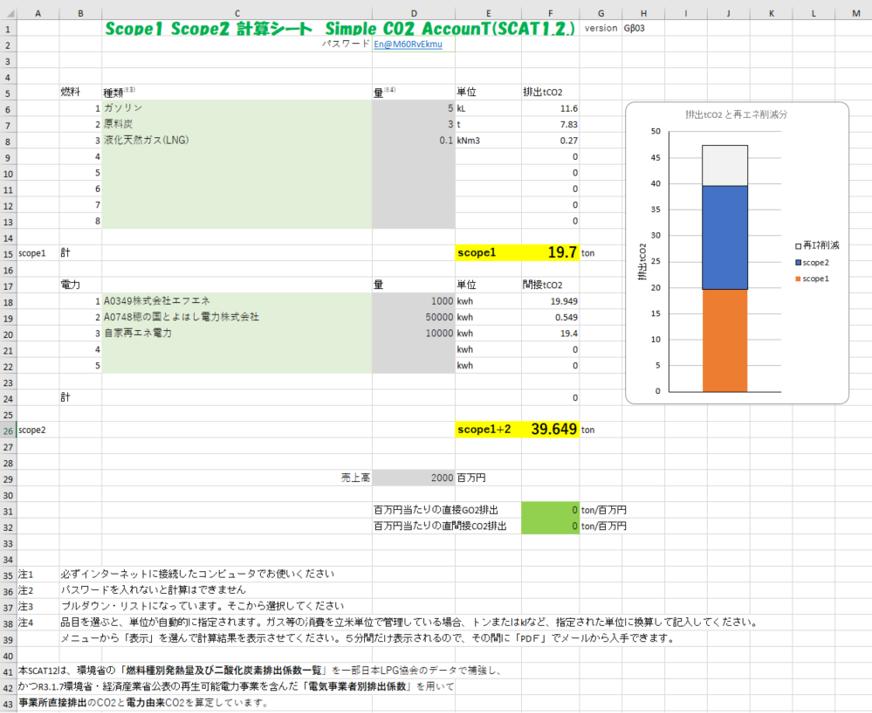
A universal Excel sheet was used to perform the calculations.
Generative AI has the power to indirectly infer information that is not explicitly provided through natural language processing (NLP) for large-scale big data. In particular, they integrate diverse information from publicly available industry reports, technical papers, patent information, and online corporate reports to enable data estimation in the LCA process. These AIs automatically learn the knowledge necessary to build models and highly predict unknown information, thus contributing to improving the accuracy of LCA analysis.
The main advantages of using generative AI for data mining are as follows
The first is the ability to discover hidden patterns and trends in large volumes of unstructured data. This can complement process details not included in existing databases. Second, AI can analyze public information from around the world in real time, allowing it to respond quickly to new technologies and changing market trends. Third, even when it is difficult to acquire information through interviews or on-site surveys, AI can provide highly accurate estimates while keeping costs down.
In addition, generative AI goes beyond the limits of traditional data processing to provide integrated insights into complex systems and processes. In the CFP evaluation of products containing technology, AI-based estimation is a powerful tool for understanding the detailed environmental impact of each process. This will enable reliable results even in cases where accurate analysis is difficult due to lack of data. In the future, the use of generative AI is expected to play an important role in improving the efficiency and accuracy of LCA assessments.
While there are many benefits to using generative AI for LCA data mining, there are also several concerns. These concerns should be considered in terms of the predictive accuracy of AI, ethical issues, reliability of information, and transparency and interpretability of data.
First, there is the issue of accuracy of estimation by generative AI: AI learns patterns based on past data and makes estimations, but the accuracy of predictions depends heavily on the quality of the data. process data required for LCA varies widely from industry to industry, and it can be difficult to keep up with the latest technologies and company operations. It can be difficult to keep up with the latest technologies and company operations. Therefore, it is important to verify the accuracy of AI-based estimation results, which requires human expertise.
Second, the ethical issues associated with the use of AI cannot be ignored: AI collects and learns public information on the Internet, which may include information that has been disclosed in a manner not intended by the company or data that is highly confidential. The incorporation of such data into AI training poses the risk of indirect estimation and use of confidential corporate information. This could result in violations of privacy and information handling regulations.
Third, the reliability and interpretability of AI-provided results is also an important concern: AI-generated estimation results often function as a “black box,” and their decision criteria and estimation process tend to be opaque; because LCA is a scientific analysis, transparency and reproducibility of results are important, but if AI However, if it is not possible to explain how the estimates are derived, the reliability of the results may be undermined. Lack of transparency is also a serious problem when the results of LCA analysis influence corporate decisions and policies.
In addition, AI-based estimation involves the risk of bias because it relies on specific data; if the data set used by the AI for training is biased, the results may also be biased. This risks producing results that disadvantage certain countries or companies, or underestimating the true environmental impact.
Finally, the introduction of generative AI also entails a technical cost: a sophisticated computing environment and specialized knowledge are required to utilize AI, which is a heavy burden for the companies and organizations that implement it. In addition, in order to effectively utilize the results of AI analysis, know-how is also required to accurately interpret the results and apply them in a manner suitable for LCA purposes.
As discussed above, the use of generative AI for data mining in TMR and TCFP opens up many possibilities, but also entails multiple challenges, including accuracy of predictions, ethical issues, transparency, risk of bias, and implementation costs. To address these challenges, it is important to fully understand the use of AI and its limitations, and to strengthen its linkages with human expertise. In addition, transparent data management and guidelines for the proper handling of information must be developed.
First, 1) we assumed a range for the data values and allowed the AI to present not only a single estimate, but also its range (upper and lower bounds). This allows for uncertainty to be considered in TMR and TCFP calculations and allows for analysis that includes worst- and best-case scenarios. For example, if energy consumption varies by region or operating conditions, the range can be taken into account for a more reliable assessment.
Next, 2) Validity determination was conducted using expert knowledge. Experts familiar with LCA and manufacturing processes scrutinized the estimated data of the generative AI to determine whether they were in line with reality, and eliminated inappropriate data or made adjustments to ensure the reliability of the results. For example, experts evaluated AI’s estimation results for the percentage of rare metals used with respect to DCR and checked them against past performance data and the latest technical information.
Furthermore, 3) Prompting was devised to reduce bias in the AI’s learning process. Specifically, the AI was designed to input diverse information from multiple data sources to avoid bias toward a single viewpoint. For example, by combining environmental impact data from different regions and operational information from different companies, the AI avoids dependence on specific markets or technologies and provides comprehensive estimates.
The following measures were taken to devise prompts: First, the search scope of the generative AI was limited to highly specialized information in the form of “You are an expert in resource engineering and materials engineering and are familiar with LCA, industrial realities, and patents,” and the search priority for general blogs and non-specialized articles was lowered to Setting. This facilitated the acquisition of high-quality data.
Second, we specified in the target process designation “as a method of obtaining objects commonly used in industries around the world,” so that the AI would not rely on laboratory or idea-level information. This reduced the risk that commercially viable technologies and practical data would be prioritized and that information from the research stage, which has not yet been put to practical use, would be mixed in.
Furthermore, as a third measure, when the numerical value presented by the AI was far from the expert’s knowledge, we instructed the AI to consider the possibility that other information similar to the numerical value may have been mixed in, and to write the name and reaction equation of the relevant reaction. This had the effect of encouraging the AI to provide appropriate process-based information and preventing the inclusion of less relevant information.
Thus, data processing that maximizes the power of generative AI while incorporating expert judgment and a variety of data combinations is an effective method for ensuring high reliability in TMR and TCFP evaluations of complex materials.
A generic Excel table was developed to calculate the data thus obtained. The sheet consists of “element name J” and “configuration name K” and data from L to AH, where all elements forming the system are described.
Element” is a superordinate concept of “configuration. In other words, the substances and processes required to form an “element” become the “configuration name,” and are described one line after another, starting from the line following the element. This “composition” then becomes an “element,” and the next level of “composition” is created.
The “composition” is given a final quantity N, which is the quantity required for the unit of the element (element quantity L). This value is not directly input, but is given as a value in the range of Q below and R above. This is because the amount of substances and other materials fed into the process is not firm, and there is a range of values. In some cases, it is not possible to give a range of values, in which case only the lower Q is used. The quantity O is a single numerical value obtained by taking the synergistic average of the lower Q and the upper R. In addition, some inputs, such as organic solvents and water, are circulated, in which case the circulation rate % is entered in the circulation rate S, so that the circulation loss can be reflected in the final amount N as the amount used. In the “Composition” field, only the composition name K, lower Q, upper R, and circulation rate S are entered, while upper R and circulation rate S may be omitted.
The “Element Name” is automatically generated from the “Configuration” by the automatic generation mechanism described below, except for the first one (for the CFP). When an “Element Name” is generated, it must first be checked to see if it is in an existing database. If the CFP for the element is available from an existing database, the value is entered into the “CO2 intensity (AD)” field, and a 1 is placed in the Q column to complete the input for this “element.
If there is no existing database, first enter the standard amount of the element that will be the unit of composition in columns Q, (and R if there is a range). The unit of measure should be consistent only between this element and the underlying composition, and there is no need to worry about the relationship with other elements.
If it is not in the database, the energy input of the process is first entered in the “Element” row, where Q is the standard charge of the element as described above. The same as in the case of quantity O, the electricity quantity T and the fuel quantity Y are put into U, V and AA, AB with an upper and lower range, and then unified by taking a synergistic average. The case of the generated CO2(AC) is the case where there is a CO2 generation other than combustion. Note that soil and stone (AE,AF,AG) are not relevant in this case, as they are prepared for calculations that also include resource efficiency.
Composition number H is a number assigned to a “composition,” and the same number is automatically assigned when there are identical composition names. The reference element line F indicates the number of the “element” of the “configuration” corresponding to the line, and represents a hierarchical structure in which a “configuration” becomes an “element” based on this number and gives birth to another child “configuration.
The upper element line E is the line number of the “element” to which the “configuration” belongs.
The next element line D is the line number where the next element in the sequence appears. This allows the “Calculation” sheet to calculate the sum of the “configurations” belonging to that “element”.
The maximum number C is to represent the maximum number up to the current line as a reference in order to give the “configuration number” H for a new “configuration”.
Element number A is the number of the element.
These are calculation systems that are automatically generated whenever a new “configuration” is written to the line below an “element” that is not in the database at the end of the “configuration” and automatically add a new “element” corresponding to the “configuration,” and the actual total is also calculated using this data, especially the “reference element line” F. The actual accumulation is calculated using this data, in particular, the “reference element row” F.
The overall TCFP calculation results are represented in two rows of column AS ({CFP}), which is the sum of the CO2 generation calculated from the sum of the electricity sources (column AQ) and the CO2 amount from fuel and other (non combustion, intensity) (column CP2FP AR).
=AQ2*fuel!D$15+AR2
The power FP (AQ column) is the part that accumulates power. This calculation is different for “elements” and “configurations. In the case of an “element,” the power footprint of the “element” is the sum of the power input in the process of the “element” plus the power footprint of the “configuration” included in the “element” multiplied by the configuration quantity N, which is then divided by the unit L of the “element” to obtain the power footprint of the “element. In other words, by calling up the power footprint of this “element” in the hierarchy above it and multiplying it by the “configuration amount” as the “configuration” in that hierarchy, the power footprint for that configuration is the cough of the configuration amount, and it becomes a minute of the calculation for the “element” in the hierarchy above it. In other words,
=IF(AZ2<>””,AH2*(T2+IF(AZ2>ROW()+1,SUM(AQ3:INDIRECT(“AQ”&AZ2-1))),0))/L2,M2*INDIRECT(“AQ”&BB2))
Here, the “Next Element Row D”, “Upper Element Row E”, and “Reference Element Row F” from the “Input” sheet are copied here, respectively.
AR(CO2FP) is the same calculation for fuel generated CO2, generated CO2, and specific CO2.
=IF(AZ2<>””,AH2*(W2+AC2+AD2+IF(AZ2>(ROW()+1),SUM(AR3:INDIRECT(“AR”&AZ2-1)),0))/L2,M2*INDIRECT(“AR”&BB2))
A similar calculation is performed for TMR in the AT to AV column. BQ to BS are the intermediate TCFPs and TMRs obtained in the course of this calculation, which can be incorporated into the database and used for future calculations.
This excel sheet is also available on the web, where you can see how each element is organized.
The reason why TCFP is used here instead of CFP is that now that it is possible to calculate up to the resource end, it is possible to set a conventional boundary and perform a cutoff and compare it to what seems to be a system Sakashita CFP in the existing database, which has limitations, so that it becomes a large number and does not confuse existing efforts. This is so as not to confuse existing efforts.
Let us show one example of this in terms of electricity consumption.
The global average TCFP for electricity is 7.27 kgCO2/kwh. The composition of this figure is as follows: 0.56 is coal, 0.53 is natural gas, 0045 is oil, 0.05 is biomass, 0.07 is nuclear, and 6.02 is renewable energy. Of the total, 0.56 kgCO2/kwh is from combustion, 76% from coal, 21% from natural gas, 54% from oil, and 15% from biomass, while nuclear power and renewable energy are all from equipment and processes. In nuclear power, 35% is equipment, 41% is enriched uranium, 24% of enriched uranium is natural uranium, 13% is fluorine, and 8% is processing (initial investment). 61% of renewable energy is copper, 32% is PV cells, 89% of which is high-purity silica, and 73% is hydrofluoric acid to remove impurities from the silica. In this view, the power portion in the CFP so far is inadequate, corresponding to Scope 1 and 2, and a more accurate TCFP can be obtained with the Scope 3 concept by following to the resource end. Here we have broken through the arbitrariness barrier of setting “system boundaries”.