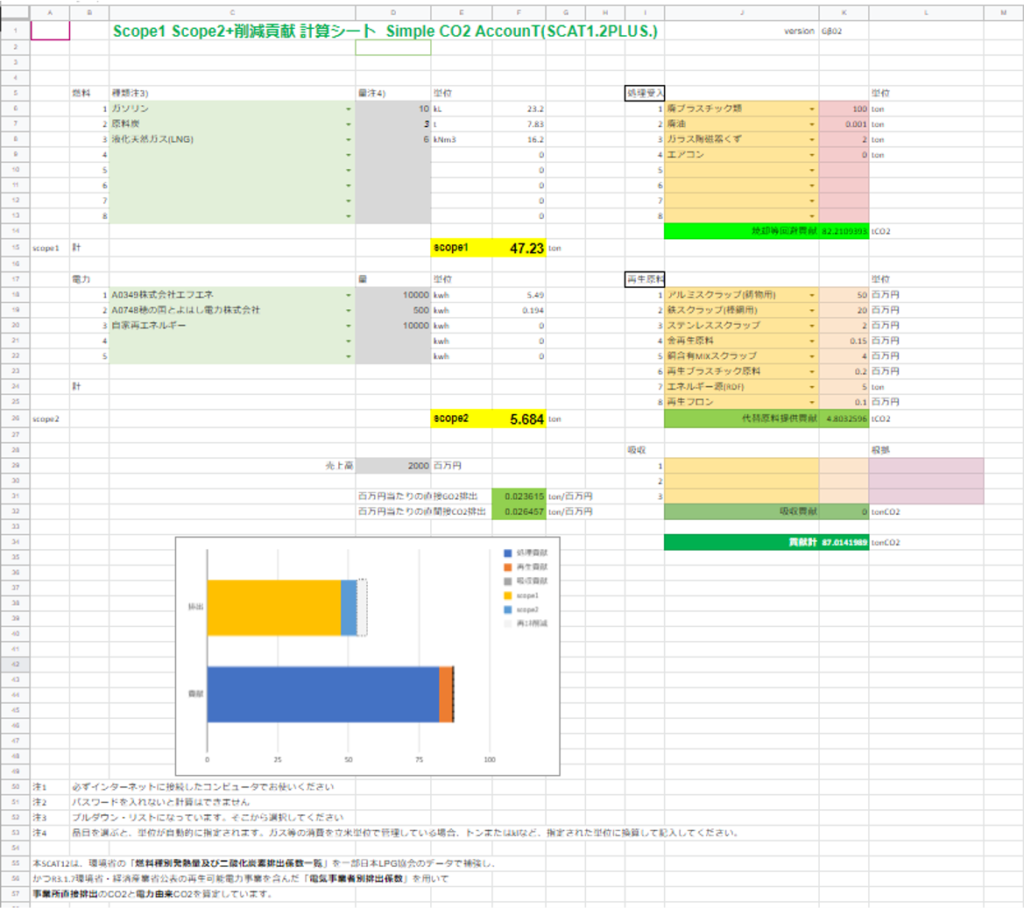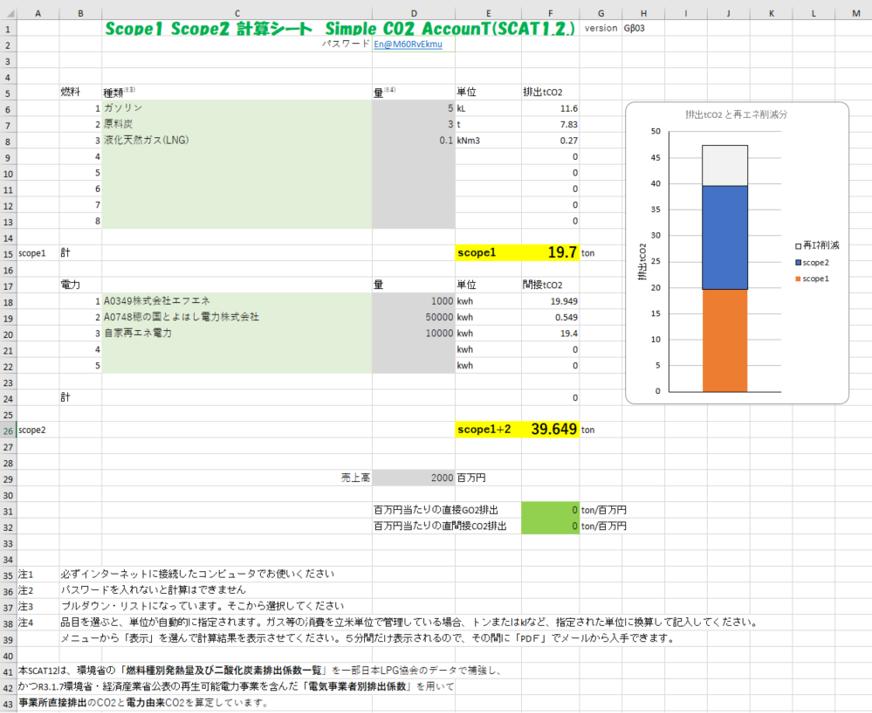
計算の根拠データ
計算実施エクセルシート
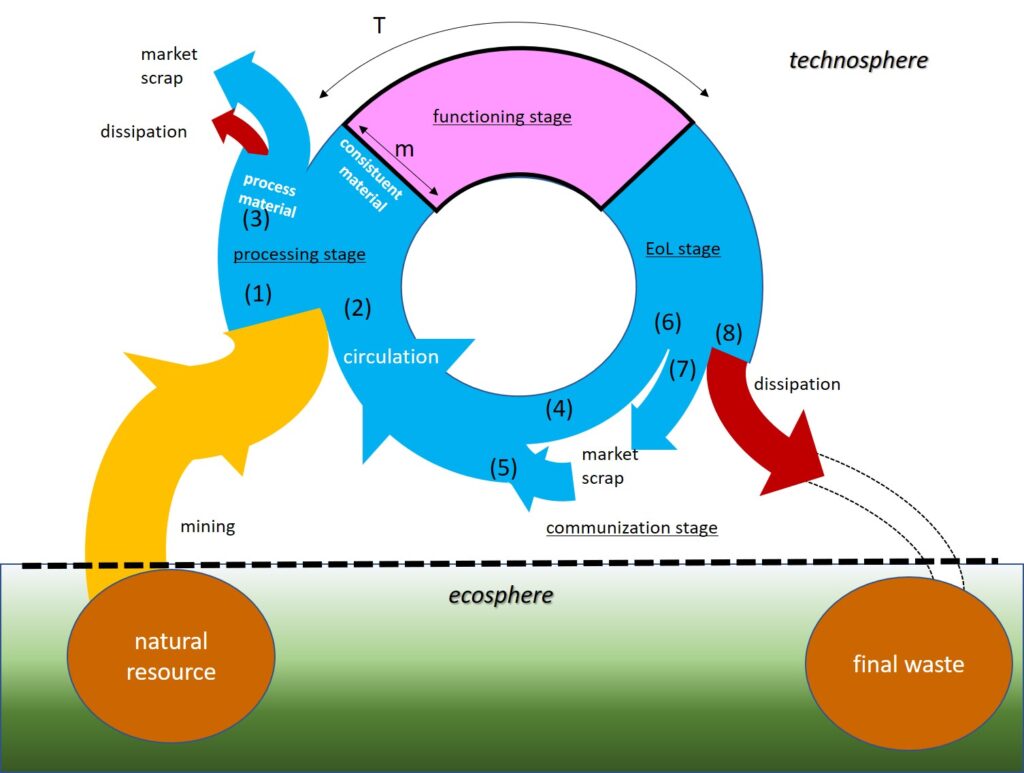
サーキュラー・エコノミーは、安価で入手しやすかった鉄、石油という物質依存のリニアな経済からの脱却である。
そのためには、これまで「安価で入手しやすい」と思ってきた資源などの自然の恵みが、どれだけ高価なものであったかを認識しなければならない。
資源効率やサーキュラリティは、人間経済圏の中だけで議論するのではなく、地球環境圏との大循環への依存度との関係で議論されねばならない。
有名なバタフライ図もバイオマスとの拡張は行ったが、この地球環境圏との循環依存度に関しては、残念ながら不十分である。また。地球環境圏との循環依存度を定量的に把握することは、ネイチャーポジティブのとりくみにとっても、われわれの現在地を認識するうえで大きな意味がある。
では、その地球環境圏との循環依存度を定量化する指標があったのか。答えはイエスである。すでに1990年代にドイツの打ったーバール研究所の創始者シュミットブレークがエコロジカルリュックサックという概念を発表し、それをワイツゼッカーらが物質集約度として発展させ、それを四分の一にするも10分の一にするとしてファクター4、ファクター10などの概念を生み出してきて、それが現在のサーキュラーエコノミーの源流の一つになっている。
この概念は、ブッターバール研究所の後継者や、わたくしNIMSの原田に受け継がれ。Total Material Requirementとして、その定量的な値も算定され、日本の環境基本計画では、補助指標としても使われた。
しかし、物質利用と循環の議論は、人間経済圏の中でのアベイラビリティと有効利用にシフトしていき、TMRは環境ファクターの一つとみなされて、その環境ファクターの視点では毒物学的視点と直接に結び付けられる因子ではないとして、議論の後継に退くようになっていった。 サーキュラーエコノミーとして、マテリアルインテンシティを包含する概念が重要視されるようになっても、このTMRの概念はごく一部の研究者以外注意を払わないものとなっていた。
しかし、ネイチャーポジティブがサーキュラー・エコノミーとともに叫ばれるようになると、サーキュラーエコノミーのことは、「安価で手に入りやすい物質とエネルギー」に焦点を当てる必要が出てくる。人間経済がいかに自然に依存していたかということを知る定量的手法としてTMRの再評価が必要であり、その低減策として資源効率は語られねばならない。
では、TMRとは何か、ある物質や製品を製造するために投入される資源の総量である。ここで資源を定量化するために、土石と水の量を用いる。バイオマスももちろん資源であるが、人間経済圏と地球環境研の境界に固定して存在しておらず定量しにくく、かつバイオマスは土壌や水によって生み出され育まれる。土壌と水をどのくらい移動させているかを地球環境圏と人間の経済活動の第一次近似値として定量する。かつては、「海岸の砂論」というものがあり、海岸の砂を一握り右から左に動かしても何の環境影響も与えない場合もある数値として、TMRは環境ストレス因子には加えられないとされてきた。しかし、ネイチャーポジティブが叫ばれる今。海岸の砂の中にも多様な生態系があることは、もうみんな知っている。
具体的には、鉱石採掘や、排水処理など人間活動と地球環境圏との境界にあるところから、土石と水の関与量を積み上げていく。たとえば鉄の生産を考えると、鉄鉱石、コークス、石灰石、水が投入されスラグ処理が必要となる。鉄鉱石は、鉄鉱山で採掘されたのちに先行される。選鉱には水、浮選剤が使用されスラッジ処理が発生する。鉱石の採掘は大量の土石を使用することになり、さらには軽油で運搬が頻繁に行われ、爆薬(ANFO)、潤滑油、さらに水が使用される。ANFOの製造には、硫酸アンモニウムと軽油が使用される。また、浮選剤としては、エタノール、二硫化炭素、水酸化ナトリウムから合成される。硫酸アンモニウムはアンモニアと硫酸を原料とし、アンモニアは、窒素と水素から合成され、硫酸は硫黄と水から合成され、廃酸処理が生じる。硫黄は鉱山から採掘され、窒素と酸素は空気から低温分留される。また、軽油も原油から分留されるが、原油の採掘も掘削液やベントナイトや、凝集剤が投入され、スラッジ処理も生じる。すべては触れられなかったし、これらすべてに電力の投入がある、このように、土石、水、空気という天然資源までさかのぼることができ。それらの総量を総和したものがTotal Material Requirement である。
この手法は、その資源端部分からCO2の発生を追っていけば、CFP(カーボンフットプリント)に適用することも可能であり、この方法により取得されたカーボンフットプリントをTotal Carbon Foot Printと名付ける。なぜCFPではなくTCFP七日については後述する。
ここで、TMRが普及しなかったもう一つの理由を述べよう。それはデータの入手の難しさである。データの入手のむつかしさには二つある。ひとつは、煩雑な入れ子構造である。
もうひとつは、地球環境圏との境界の情報取得の難しさである。鉱山の鉱石品位がどのくらいかまでは、公開されているとしても、その鉱石を採掘ためにどれだけの剝土や掘削土があるかは経営の課題でもあり殆ど公表されていない。それらの理由でTMRの基礎数値を計算したり見直したりする研究者は極めて限られていたのである。
そして、その状況が一変した。生成系AIと呼ばれることの多い、大規模言語処理型AIの誕生である。ついつい「生成系」ということに注目が行くが、本質的に、゛っでーちを基礎とした大量言語処理を行うaiである。すなわち、「生成」の背景には「データマイニング」と収集があるのである。そのaiをうまくブロンプティングして、データマイニングの仕方をコントロールすれば、これまで得ることのできなかった鉱山データや廃棄物処理データを収集させることができる。私は、これをデータマイニングaiと呼ぶ。
生成系AIは、大規模なビッグデータを対象とした自然言語処理(NLP)により、明示的に提供されていない情報を間接的に推定する力を持つ。特に、公開されている産業レポート、技術論文、特許情報、オンラインの企業報告書などから多様な情報を統合し、LCAのプロセスにおけるデータの推定を可能にする。こうしたAIは、モデル構築に必要な知識を自動で学習し、未知の情報を高度に予測するため、TMR分析の精度向上に貢献する。
生成系AIをデータマイニングに用いる主なメリットは以下の通りである。
第一に、大量の非構造化データから隠れたパターンやトレンドを発見できる点である。これにより、既存のデータベースに含まれないプロセスの詳細を補完できる。第二に、AIは世界中の公開情報をリアルタイムに解析できるため、新たな技術や市場動向の変化に迅速に対応できる。第三に、ヒアリングや現場調査による情報取得が難しい場合でも、AIを使うことでコストを抑えつつ、高精度な推定が可能になる。
さらに、生成系AIは従来のデータ処理の限界を超え、複雑なシステムやプロセスに対する統合的な洞察を提供する。高度な技術を含む製品のTMR評価では、各工程の詳細な環境負荷を把握するためにAIによる推定が大きな力を発揮する。これにより、データ不足が原因で正確な分析が難しいケースでも、信頼性の高い結果を得ることが可能となる。今後、生成系AIの活用はLCA評価の効率化と精度向上において重要な役割を果たすと考えられる。
生成系AIをLCAのデータマイニングに活用する際には、多くのメリットがある一方で、いくつかの懸念も存在する。これらの懸念は、AIの予測精度や倫理的な問題、情報の信頼性、そしてデータの透明性と解釈可能性の観点から考慮されるべきである。
第一に、生成系AIによる推定の精度の問題が挙げられる。AIは過去のデータに基づいてパターンを学習し、推定を行うが、予測の精度はデータの質に大きく依存する。LCAに必要なプロセスデータは、産業ごとの差異が大きく、最新の技術や企業のオペレーションに追従するのは難しい場合がある。そのため、AIによる推定結果が正確であるかどうかの検証が重要であり、これには人間の専門知識が必要となる。
第二に、AIの利用に伴う倫理的問題も無視できない。AIはインターネット上の公開情報を収集し学習するが、その中には企業の意図しない形で公開された情報や、機密性の高いデータが含まれる可能性がある。このようなデータがAIの学習に組み込まれることで、企業の秘密情報が間接的に推定・利用されるリスクが生じる。これにより、プライバシーや情報の取り扱いに関する規制への違反が発生する可能性がある。
第三に、AIが提供する結果の信頼性と解釈可能性も重要な懸念である。AIが生成する推定結果は「ブラックボックス」として機能することが多く、その判断基準や推定過程が不透明になりがちである。LCAは科学的な分析であるため、結果の透明性と再現性が重要だが、AIによる推定がどのように導き出されたのかを説明できない場合、その結果の信頼性が損なわれる恐れがある。また、LCAの分析結果が企業の意思決定や政策に影響を与える場合、その透明性が欠如することは重大な問題となる。
さらに、AIを用いた推定は、特定のデータに依存するため、バイアスのリスクも含んでいる。AIが学習に使用するデータセットが偏っている場合、結果も偏ったものになる可能性がある。これにより、特定の国や企業が不利になる結果が出る、あるいは本来の環境負荷が過小評価されるリスクがある。
最後に、生成系AIの導入には技術的コストも伴う。AIを活用するためには、高度な計算環境や専門的な知識が必要であり、これを導入する企業や組織にとっては負担が大きい。また、AIによる分析結果を有効活用するためには、結果を正確に解釈し、LCAの目的に合った形で応用するためのノウハウも求められる。
以上のように、生成系AIをLCAのデータマイニングに利用することは、多くの可能性を開く一方で、予測の精度、倫理的課題、透明性の確保、バイアスのリスク、導入コストといった複数の課題を伴う。これらの課題に対処するためには、AIの利用とその限界を十分に理解し、人間の専門知識との連携を強化することが重要である。また、透明性のあるデータ管理と、情報の適切な取り扱いに対するガイドラインの整備が求められる。
まず、1) データの値に範囲を設定することを前提とし、AIには単一の推定値だけでなく、その範囲(上下限値)を提示させた。これにより、LCA計算で不確実性を考慮し、最悪および最善のシナリオを含む分析が可能となる。たとえば、エネルギー消費量が地域や操業条件で異なる場合、その幅を考慮することで、より信頼性の高い評価が行える。
次に、2) 専門家知識を活用した妥当性判断を実施した。生成系AIの推定データが現実に即しているかどうかを、LCAや製造工程に精通した専門家が精査し、不適切なデータを排除したり、調整を加えることで、結果の信頼性を確保した。たとえば、希少金属の使用割合について、AIの推定結果を物質工学専門家が評価し、過去の実績データや最新の技術情報に照らして確認した。
さらに、3) プロンプテーションの工夫により、AIが学習する際のバイアスを軽減する手法を採用した。具体的には、複数のデータソースから多様な情報をAIに入力し、一つの視点に偏らないように設計した。たとえば、地域ごとの環境負荷データや異なる企業の操業情報を組み合わせることで、特定の市場や技術への依存を避け、包括的な推定が可能となる。
プロンプテーションの工夫として、以下のような措置を講じた。1つ目に、「あなたは資源工学と物質工学の専門家で、LCAや産業実態、特許にも精通しています」という形で、生成系AIの検索範囲を専門性の高い情報に限定し、一般的なブログや非専門的な記事の検索優先度を低く設定した。これにより、質の高いデータの取得を促進した。
2つ目に、「世界の産業で一般的に対象物を得る手法として」と対象プロセスの指定に明記し、AIが実験室やアイデアレベルの情報に依存しないようにした。これにより、商業的に成立した技術や実用的なデータが優先され、実用化されていない研究段階の情報が混入するリスクを軽減した。
さらに、3つ目の対策として、AIが提示する数値が専門家の知識とかけ離れている場合には、その数値に類似する他の情報が混入している可能性を考慮し、該当する反応の名前や反応式を書かせるよう指示した。これにより、AIが適切なプロセスに基づく情報を提供することを促し、関連性の低い情報の混入を防ぐ効果が得られた。
このように、生成系AIの力を最大限に引き出しながら、専門家の判断と多様なデータの組み合わせを取り入れたデータ処理は、複雑な材料のCFP評価において高い信頼性を確保するための有効な手法である。これにより、不確実性の管理とバイアスの軽減が両立し、LCA結果の精度が向上することが期待される。
こうして取得したデータは、webサイトにすべて記してある。物質工学の専門家として私のチェックは行われているが、すべての皆さんの目で、データの妥当性を検討してほしい。
計算の実行に当たっては普遍的なエクセルシートをさくせいした。
生成系AIは、大規模なビッグデータを対象とした自然言語処理(NLP)により、明示的に提供されていない情報を間接的に推定する力を持つ。特に、公開されている産業レポート、技術論文、特許情報、オンラインの企業報告書などから多様な情報を統合し、LCAのプロセスにおけるデータの推定を可能にする。こうしたAIは、モデル構築に必要な知識を自動で学習し、未知の情報を高度に予測するため、LCA分析の精度向上に貢献する。
生成系AIをデータマイニングに用いる主なメリットは以下の通りである。
第一に、大量の非構造化データから隠れたパターンやトレンドを発見できる点である。これにより、既存のデータベースに含まれないプロセスの詳細を補完できる。第二に、AIは世界中の公開情報をリアルタイムに解析できるため、新たな技術や市場動向の変化に迅速に対応できる。第三に、ヒアリングや現場調査による情報取得が難しい場合でも、AIを使うことでコストを抑えつつ、高精度な推定が可能になる。
さらに、生成系AIは従来のデータ処理の限界を超え、複雑なシステムやプロセスに対する統合的な洞察を提供する。技術を含む製品のCFP評価では、各工程の詳細な環境負荷を把握するためにAIによる推定が大きな力を発揮する。これにより、データ不足が原因で正確な分析が難しいケースでも、信頼性の高い結果を得ることが可能となる。今後、生成系AIの活用はLCA評価の効率化と精度向上において重要な役割を果たすと考えられる。
生成系AIをLCAのデータマイニングに活用する際には、多くのメリットがある一方で、いくつかの懸念も存在する。これらの懸念は、AIの予測精度や倫理的な問題、情報の信頼性、そしてデータの透明性と解釈可能性の観点から考慮されるべきである。
第一に、生成系AIによる推定の精度の問題が挙げられる。AIは過去のデータに基づいてパターンを学習し、推定を行うが、予測の精度はデータの質に大きく依存する。LCAに必要なプロセスデータは、産業ごとの差異が大きく、最新の技術や企業のオペレーションに追従するのは難しい場合がある。そのため、AIによる推定結果が正確であるかどうかの検証が重要であり、これには人間の専門知識が必要となる。
第二に、AIの利用に伴う倫理的問題も無視できない。AIはインターネット上の公開情報を収集し学習するが、その中には企業の意図しない形で公開された情報や、機密性の高いデータが含まれる可能性がある。このようなデータがAIの学習に組み込まれることで、企業の秘密情報が間接的に推定・利用されるリスクが生じる。これにより、プライバシーや情報の取り扱いに関する規制への違反が発生する可能性がある。
第三に、AIが提供する結果の信頼性と解釈可能性も重要な懸念である。AIが生成する推定結果は「ブラックボックス」として機能することが多く、その判断基準や推定過程が不透明になりがちである。LCAは科学的な分析であるため、結果の透明性と再現性が重要だが、AIによる推定がどのように導き出されたのかを説明できない場合、その結果の信頼性が損なわれる恐れがある。また、LCAの分析結果が企業の意思決定や政策に影響を与える場合、その透明性が欠如することは重大な問題となる。
さらに、AIを用いた推定は、特定のデータに依存するため、バイアスのリスクも含んでいる。AIが学習に使用するデータセットが偏っている場合、結果も偏ったものになる可能性がある。これにより、特定の国や企業が不利になる結果が出る、あるいは本来の環境負荷が過小評価されるリスクがある。
最後に、生成系AIの導入には技術的コストも伴う。AIを活用するためには、高度な計算環境や専門的な知識が必要であり、これを導入する企業や組織にとっては負担が大きい。また、AIによる分析結果を有効活用するためには、結果を正確に解釈し、LCAの目的に合った形で応用するためのノウハウも求められる。
以上のように、生成系AIをTMRやTCFPのデータマイニングに利用することは、多くの可能性を開く一方で、予測の精度、倫理的課題、透明性の確保、バイアスのリスク、導入コストといった複数の課題を伴う。これらの課題に対処するためには、AIの利用とその限界を十分に理解し、人間の専門知識との連携を強化することが重要である。また、透明性のあるデータ管理と、情報の適切な取り扱いに対するガイドラインの整備が求められる。
まず、1) データの値に範囲を設定することを前提とし、AIには単一の推定値だけでなく、その範囲(上下限値)を提示させた。これにより、TMRやTCFP計算で不確実性を考慮し、最悪および最善のシナリオを含む分析が可能となる。たとえば、エネルギー消費量が地域や操業条件で異なる場合、その幅を考慮することで、より信頼性の高い評価が行える。
次に、2) 専門家知識を活用した妥当性判断を実施した。生成系AIの推定データが現実に即しているかどうかを、LCAや製造工程に精通した専門家が精査し、不適切なデータを排除したり、調整を加えることで、結果の信頼性を確保した。たとえば、DCRに関する希少金属の使用割合について、AIの推定結果を専門家が評価し、過去の実績データや最新の技術情報に照らして確認した。
さらに、3) プロンプテーションの工夫により、AIが学習する際のバイアスを軽減する手法を採用した。具体的には、複数のデータソースから多様な情報をAIに入力し、一つの視点に偏らないように設計した。たとえば、地域ごとの環境負荷データや異なる企業の操業情報を組み合わせることで、特定の市場や技術への依存を避け、包括的な推定が可能となる。
プロンプテーションの工夫として、以下のような措置を講じた。1つ目に、「あなたは資源工学と物質工学の専門家で、LCAや産業実態、特許にも精通しています」という形で、生成系AIの検索範囲を専門性の高い情報に限定し、一般的なブログや非専門的な記事の検索優先度を低く設定した。これにより、質の高いデータの取得を促進した。
2つ目に、「世界の産業で一般的に対象物を得る手法として」と対象プロセスの指定に明記し、AIが実験室やアイデアレベルの情報に依存しないようにした。これにより、商業的に成立した技術や実用的なデータが優先され、実用化されていない研究段階の情報が混入するリスクを軽減した。
さらに、3つ目の対策として、AIが提示する数値が専門家の知識とかけ離れている場合には、その数値に類似する他の情報が混入している可能性を考慮し、該当する反応の名前や反応式を書かせるよう指示した。これにより、AIが適切なプロセスに基づく情報を提供することを促し、関連性の低い情報の混入を防ぐ効果が得られた。
このように、生成系AIの力を最大限に引き出しながら、専門家の判断と多様なデータの組み合わせを取り入れたデータ処理は、複雑な材料のTMRやTCFP評価において高い信頼性を確保するための有効な手法である。
こうして得られるデータを計算するための、汎用的なエクセル表を開発した。シートは、「要素名J」と「構成名K」とLからAHまでのデータにより構成され、ここにシステムを形成するすべての要素が記述される。
「要素」は「構成」の上位概念である。別の言い方をすると、ある「要素」を形成するために投入される物質や必要となる処理プロセスが「構成名」となり、その要素の次の行からつぎつぎに一行ずつ取って記述される。この「構成」は、そのあとで「要素」なり、次の階層の「構成」を生み出す。
「構成」にはその要素の単位(要素量L)に必要とされる量が最終量Nとして与えられる。この値は直接入力されるのではなく下Q、上Rの範囲のある値として与えられる。これは、プロセスに投入される物質などの量は確固たるものではなく値に幅があるからである。なお幅を持って与えることができない場合もあり、その時は下Qだけに数値をいれる。量Oはこの下Q、上Rの相乗平均を取って単一数値化したものである。また、投入物の中に有機溶媒や水などで循環使用されるみのがあるので、その場合はその循環率%を循環率Sにいれると、循環ロス分を使用量として最終量Nに反映することができる。「構成」で入力するのは構成名Kと下Q、上Rおよび循環率Sだけであり、上Rおよび循環率Sはない場合もある。
「要素名」は、最初の一つ(CFP対象)を除いて、あとに述べる自動生成機構により「構成」から自動的に生成される。「要素名」がでてくると、まず、それが既存のデータベースにないかチェックする必要がある。もし、既存のデータベースからその要素のCFPが得られると、その値を「原単位CO2(AD)」に書き込み、Q列に1をいれて、この「要素」の入力は終わりである。
既存のデータベースにないばあい、まず、Q,(範囲があればRも)列に構成の単位となる要素の基準量をいれる。単位などは、この要素とその下に並ぶ構成の間だけで整合が取れておけば良く、他の要素との関係は気にしなくて良い。
データベースにない場合、まず「要素」の行にプロセスの投入エネルギーなどをいれる。Qは先述の通りの要素の基準料である。電力量T、燃料量Yが、上下の幅を持ってU,VとAA,ABに入れられ相乗平均を取って単一化されるのは量Oの場合と同じである。はっせいCO2(AC)は、燃焼以外のCO2の発生がある場合である。なお、土石(AE,AF,AG)は、資源効率も含めた計算をするための準備であり、今回は関係ない。
構成番号Hは「構成」につけられた番号であり、同じ構成名があると同じ番号が自動に振られる。 参照要素行Fは、その行に該当する「構成」が何番目の「要素」となっているかを示すものであり、この番号を元に「構成」が「要素」となってまた子の「構成」を生むという階層化された構造を表す。
上位要素行Eは、その「構成」が所属している「要素」を行番号で表したものである。
次要素行Dは、次の順番の要素が出てくる行番号である。これがあることにより「計算」シートでその「要素」に属する「構成」の和を計算することができるようになっている。
最大番号Cは新規の「構成」に対して「構成番号」Hを与えるために、参照として現在の行までで最大の番号を表しておくためのものである。
要素番号Aは、要素の番号である。
これらは、「構成」の最後に書かれてデータベースに無い「要素」の下の行に新しい「構成」が書き込まれるたびに、自動的に生成され、「構成」に対応する新しい「要素」を自動追加スルための計算システムであり、かつ、実際の積算もこのデータとくに、「参照要素行」Fを用いて計算されていく。
TCFPの総合的計算結果はAS列({CFP})の2行に表される。AS列(CFP)は電力由来の総和(AQ列)から計算されるCO2発生量と、燃料その他(燃焼以外、原単位)からのCO2量(CP2FP AR列)の和である。
=AQ2*燃料!D$15+AR2
電力FP(AQ列)は電力を積算する部分である。この計算は「要素」と「構成」では異なった計算をする。「要素」の場合は、その「要素」のプロセスで投入される電力に加えて、そこに含まれる「構成」の電力のフットプリントに構成量Nを乗じたものの総和をとり、それを「要素」の単位Lで除して「要素」の電力フットプリントにしている。すなわち、その上の階層でこの「要素」の電力フットプリントを呼び出して、その階層での「構成」として、「構成量」と乗ずることで、その構成に関する電力フットプリントかける構成量のせきとなり、その上の階層での「要素」の計算の一分となるのである。すなわち、
=IF(AZ2<>””,AH2*(T2+IF(AZ2>ROW()+1,SUM(AQ3:INDIRECT(“AQ”&AZ2-1)),0))/L2,M2*INDIRECT(“AQ”&BB2))
なおここで、ここはそれぞれ「入力」シートの「次要素行D」「上位要素行E」「参照要素行F」を引き写したものである。
AR(CO2FP)は同じ計算を燃料発生CO2および、発生CO2、原単位CO2に対して行ったものである。
=IF(AZ2<>””,AH2*(W2+AC2+AD2+IF(AZ2>(ROW()+1),SUM(AR3:INDIRECT(“AR”&AZ2-1)),0))/L2,M2*INDIRECT(“AR”&BB2))
同様の計算がTMRに対してATからAV列で行われる。また、BQからBSはこの計算の過程で得られた、中間物のTCFPとTMRであり、それを、データベースに組み入れて、今後の計算に用いることもできる。
このエクセルシートもWeb上に公開されており、それぞれの要素がどのように構成されているかを見て取ることができる。
なお、ここでCFPではなくTCFPとしたのは、こうして資源端まで計算できるようになったため、従来のバウンダリ―を設定し、カットオフを行って、限界のある既存データベースで計算したCFPらしきものと比べねと大きな数値となるため、既存の取り組みを混乱させないためである。
その一つの例を電力消費で示そう。
世界平均の電力のTCFPは7.27kgCO2/kwhにもなる。その構成を見ると0.56が石炭で、0.53が天然ガス、0045が石油、0,05がバイオマスで、0.07が原子力で再生可能エネルギーは6.02にもなる。なおそのうち燃焼分のものは全部で0.56kgCO2/kwh、石炭の76%、天然ガスの21%、石油の54%、バイオマスの15%で原子力と再生可能エネルギーはすべてが設備とプロセスによる。原子力の35%は設備、41%は濃縮ウランで濃縮ウランの24%が天然ウラン、13%がフッ素、8%が処理(初期投資分)であり、再生可能エネルギーの61%が銅、32%がPVセルでその89%が高純度シリカ、そして73%がシリカから不純物を落とすためのフッ酸となる。このようにみると、これまでのCFPでの電力分はスコープ1と2に相当する不十分なものであり、資源端まで追いかけることでスコープ3の概念でのより正確なTCFPを得ることができるのである。ここに、我々は「システム境界」の設定という任意性の壁を打ち破ることができた。